Competitive Analysis Updated April 22, 2026
Michael Timbs Founder @ Bourd
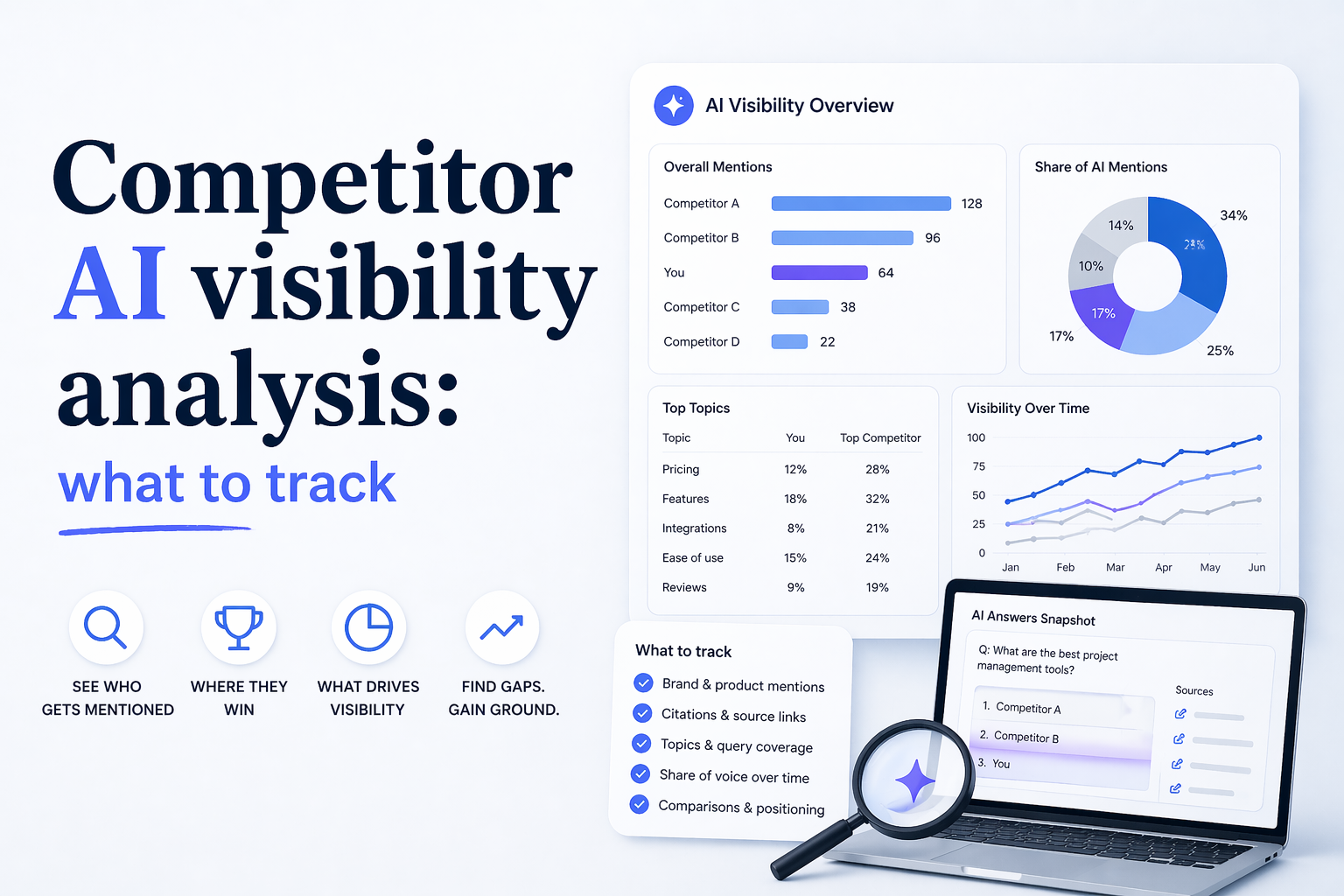
Competitor AI visibility analysis: what to track
Monitor your competitors' share of voice in AI responses and identify content gaps to exploit.
Monitor your competitors' share of voice in AI responses and identify content gaps to exploit.
Competitor AI visibility analysis is the practice of measuring how often rival brands appear and get cited in AI-generated answers from ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews. It surfaces the queries, publications, and topics driving their share of voice, and the gaps you can credibly fill. AI-generated answers now influence a large and growing share of how buyers research products, which means the brands that understand this layer first will define their category’s default answer.
Here is how to set up competitor monitoring and use it to improve your own AI visibility.
AI search rewards three distinct sets of competitors. Track all three, because the brand outranking you in Google rarely matches the brand the model cites.
Direct competitors: companies selling the same product to the same buyer. These are the brands your prospects are comparing you against in “[Category] alternatives” and “X vs Y” prompts.
Content competitors: publishers, analysts, and educators creating content in your topic areas. AI models often cite their explainers over vendor pages, which is why they matter even when they do not sell anything competitive.
AI visibility competitors: brands that consistently appear in model responses for your core prompts, even if they are not direct competitors. These are the incumbents in the model’s training data and retrieval index. They set the ceiling for your share of voice.
Once you have a list, configure your primary brand and competitors in Bourd so every run tracks mentions automatically. See Setting up brands and competitors.
Build a set of queries (in Bourd these are called prompts) that cover the full buyer journey. Aim for 15-30 in your first set, then expand from there.
Product and service queries:
Informational queries:
Comparison queries:
For prompt templates and the framework we recommend, see Writing effective prompts and Creating and managing prompts.
What to measure:
Analysis approach:
Mention Rate = (Responses mentioning the brand / Total responses analyzed) × 100Track weekly if you are actively publishing or running PR; monthly is enough for steady-state monitoring. Bourd exposes Mention Rate as a headline KPI on the Reports dashboard. See Viewing results and analytics.
What to measure:
Calculation:
Share of Voice = (Your mentions / Total mentions of all tracked brands) × 100Share of Voice is the single most useful competitive metric because it controls for prompt volume. A rising Mention Rate can hide a falling Share of Voice if the whole category is growing faster than you are. Bourd calculates Share of Voice automatically across your configured brand and competitor set. See Viewing results and analytics.
Not every mention is worth the same. A brand cited as the primary recommendation with a linked source is worth far more than a brand listed fourth in a pros-and-cons comparison.
Evaluation criteria:
Scoring system (1-5 scale):
Equally important is understanding which sources the model cited to generate that mention. Bourd aggregates every citation across your runs, grouped by domain and by URL path, so you can see which publications AI models treat as authoritative in your category. See Analyzing citations.
What to track:
Gap identification process:
The fastest version of this workflow inside Bourd: filter citations by the URLs where competitors are mentioned but your brand is not. Those are the articles AI models are using to answer questions about your category without you. See the content gap workflow in Analyzing citations.
Executive summary:
Detailed findings:
Strategic recommendations:
To produce this report on a reliable cadence, schedule your prompt set to run weekly or monthly against every model you care about. See Scheduling and automation.
Analyze competitor content that gets cited:
Content gap identification:
Direct response:
Flanking strategies:
Immediate actions:
Long-term improvements:
Manual tracking is fine for 10 prompts across 2 models. It stops scaling at around 30 prompts × 4 models × weekly: roughly 480 responses a month to read, score, and trend by hand.
Dedicated GEO platforms run your prompts across every major model, extract citations and competitor mentions, and track Share of Voice trends over time. Bourd does this for ChatGPT, Claude, Perplexity, Gemini, Grok, and Meta out of the box. For a side-by-side of how Bourd compares to Profound, Peec AI, Scrunch, PromptWatch, and Passionfruit, see the AEO tool comparison hub. If you are starting from scratch, the quickest path is:
Track the impact of your competitive response strategies:
The goal is not to match competitors prompt-for-prompt. It is to find the topics, prompts, and models where you can credibly be the default answer, and invest there.
Run this loop monthly. The citations shift as models update their training data, as retrieval indexes re-crawl, and as competitors publish. A strategy that worked last quarter may already be losing ground.
Competitor AI visibility analysis is the process of measuring how often rival brands appear in responses from AI search tools like ChatGPT, Perplexity, Gemini, and Google AI Overviews. It covers mention frequency, share of voice, citation quality, and the source URLs that models rely on to generate their answers.
Traditional SEO measures where your page ranks on a results page. AI visibility measures whether your brand gets named, described, and cited in the answer itself. A page can rank fifth in Google and still be the source AI Overviews cites, or rank first and never be mentioned by ChatGPT at all.
Monthly is the baseline for most teams. Move to weekly if you are actively publishing, running PR, or tracking a product launch. Anything less frequent than monthly will miss the drift caused by model updates and competitor content shipping.
Prioritize ChatGPT, Google AI Overviews, Perplexity, Gemini, and Claude. Add Grok and Meta if your audience skews toward their user bases. Model choice matters: a brand strong in ChatGPT can be nearly invisible in Perplexity because the two systems pull from different source sets.
Start with 15-30 prompts that span product, informational, and comparison queries. Expand from there as you identify which prompts drive meaningful traffic or surface meaningful competitive signal. Most teams end up tracking somewhere between 50 and 150 prompts once their coverage is mature.

Founder @ Bourd
Software engineer and data scientist. Founded my first company in 2014. Spent years alongside marketing and growth teams at startups before building Bourd. Posts here report what we see across the prompts Bourd runs on ChatGPT, Claude, Gemini, Perplexity, Grok, DeepSeek, Meta AI, and Google AI Mode.